


Research & Sensemaking
The first phase of work involved amassing research within the space of civic machine learning through a variety of methods.
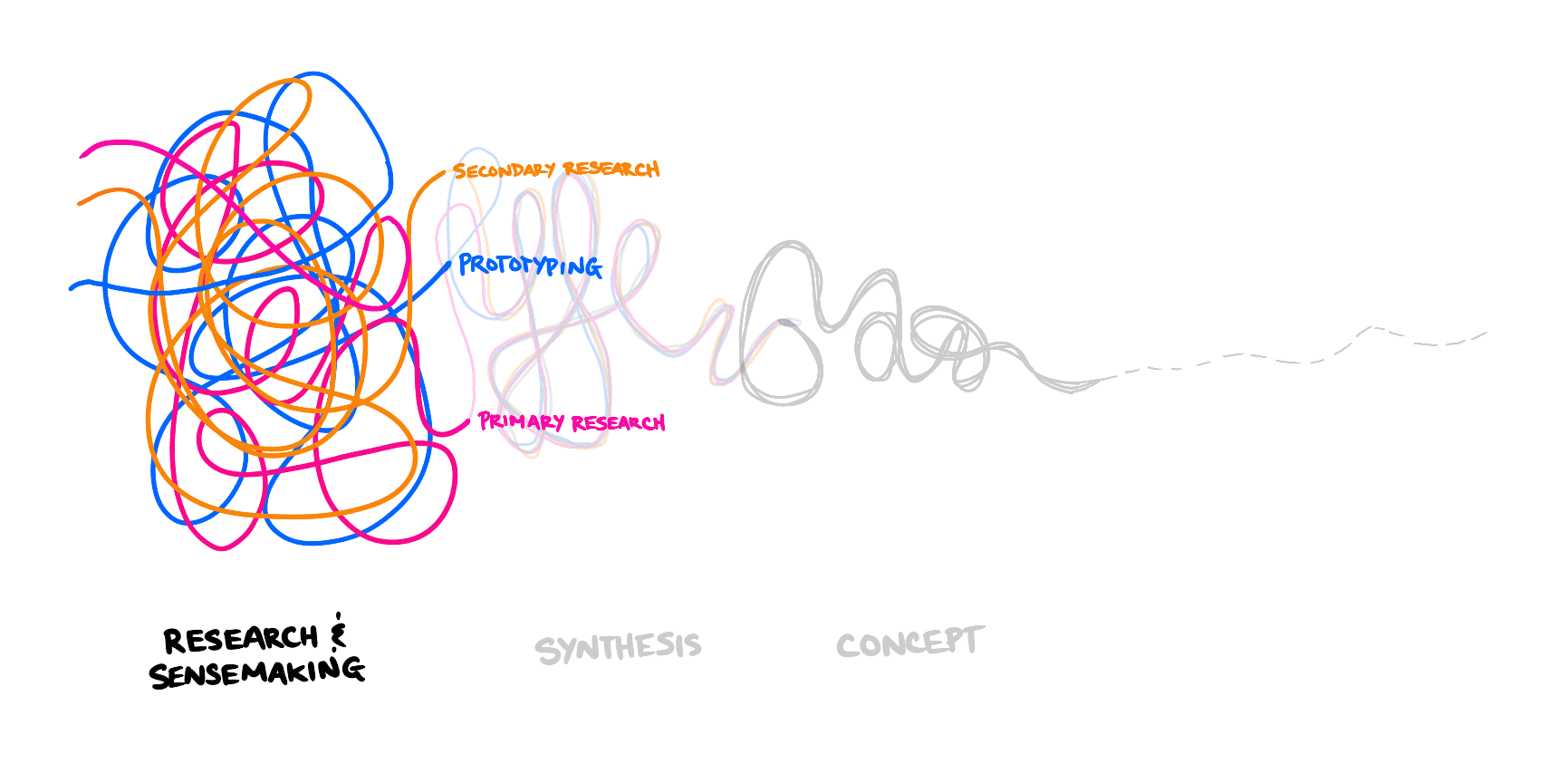
Secondary Research
Secondary research was an extremely important part of this early design work, serving as the starting point for much of the prototyping. My research engaged with the substantial amount of existing design projects on machine learning, as well as the critical scholarship happening in Science & Technology Studies, Anthropology, and New Media Studies.

Take a look at the curated are.na boards to get an overview of this research:
- Into the Black Box - broadly focused on critical perspectives on algorithms, ML and AI
- Data/Labeling/Information - research at the intersection of data labeling, datasets for ML, information, and contestability
Prototyping
Prototyping and making in this stage of work took the form of cardboard models (sometimes with simple electronics), quick web apps, or even just diagrams. These prototypes were often responding to other threads of research, delving into the materiality of the concepts I was encountering.




Some of the initial ideas that were conceived in this early stage of prototyping would consistently reappear in later stages of the design discovery process:
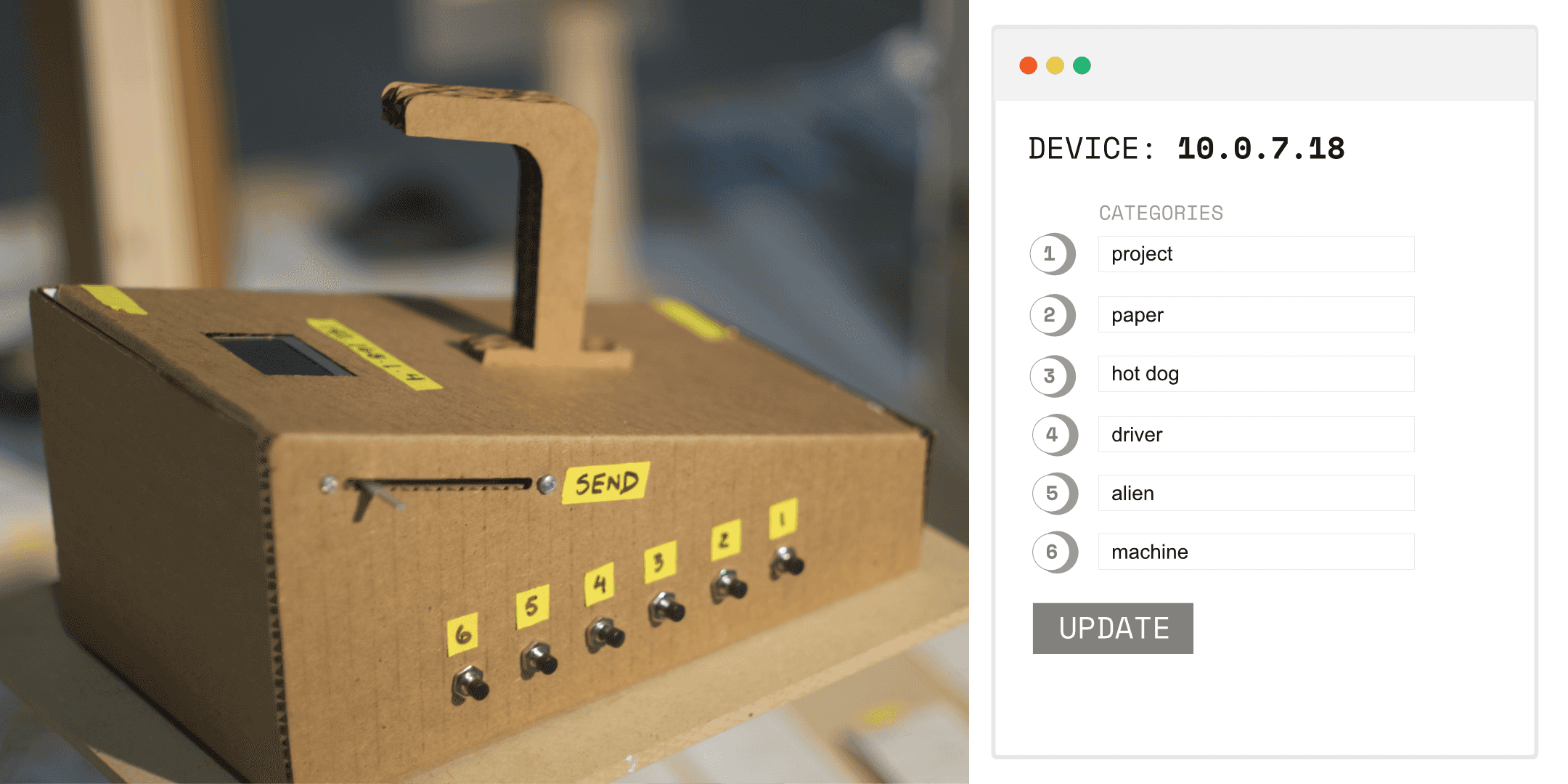
The prototype above was where I first explored ideas of data collection devices that allows user to create their own set of categories, a concept that reappears throughout the rest of the design process.
Primary Research in Context
In addition to working in the design studio, I also spent time working to understand how machine learning was being operationalized in my local community, specifically with data-driven policing. There is an active community of abolitionist organizers in Los Angeles, focused on dismantling data-driven poicing, whose work I participated in and learned from.

Much of this work took the form of collaboratively created popular education material. For more on the materials you see above, see the Algorithmic Ecology, and PredPol Is...
The learnings from this work greatly informed my design work, forming the foundational values upon which my machine learning speculations were built from. Some important takeaways included:
- An analysis of machine learning has to explicitly understand how power dynamics are embedded within the algorithm.
- Understanding an algorithm involves more than understanding the mechanics of its operation. We also need to understand how it was developed, whose interest it serves, and the historical context for its application.
- The impact on the community where an algorithm is developed needs to be centered, especially when those communities aren't always considered "users"
Sensemaking through diagrams
Creating conceptual diagrams are an incredibly useful way for me to start synthesizing some of the research and prototyping. Creating these visual metaphors and flows helped to focus my view into particular aspects of the machine learning process.
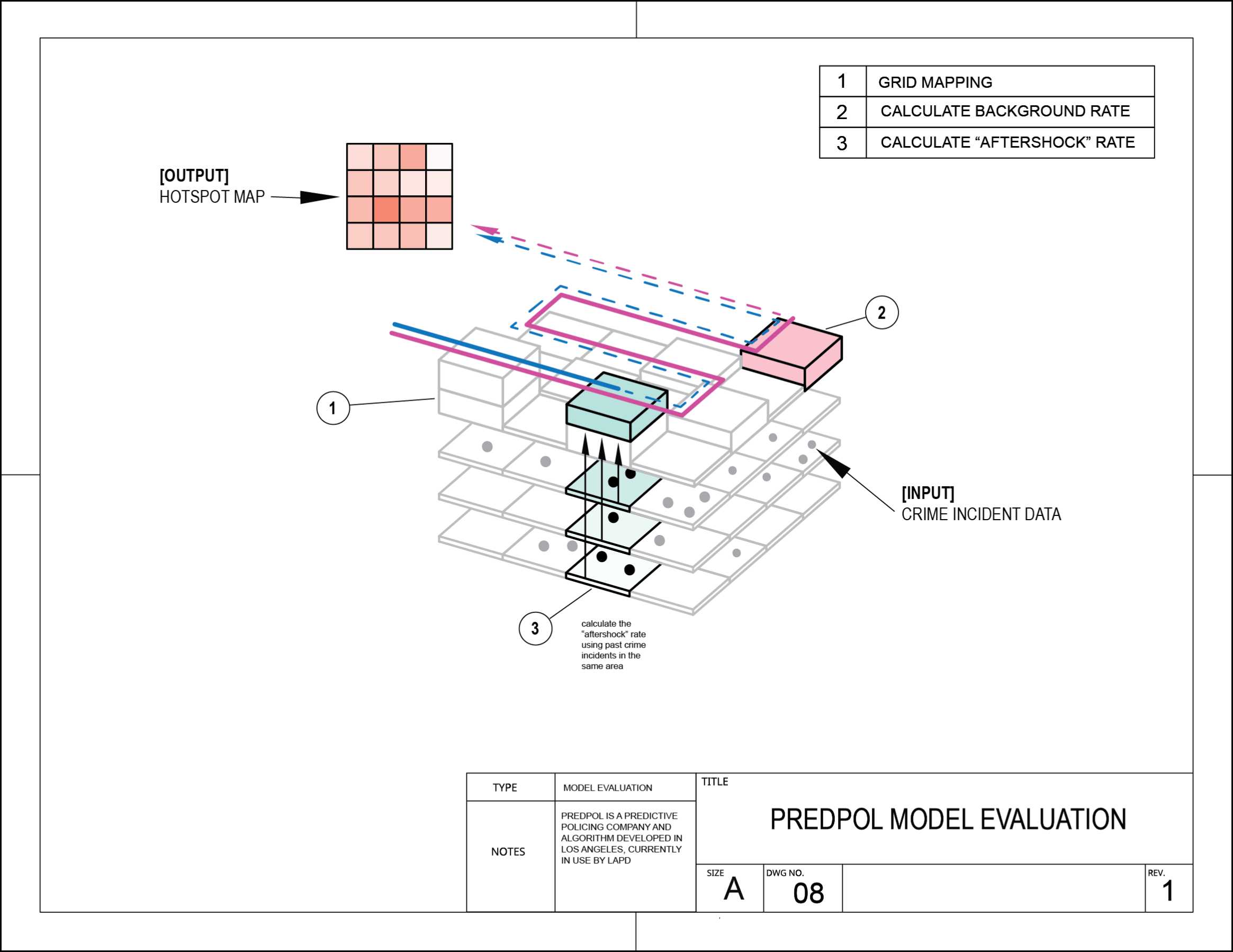
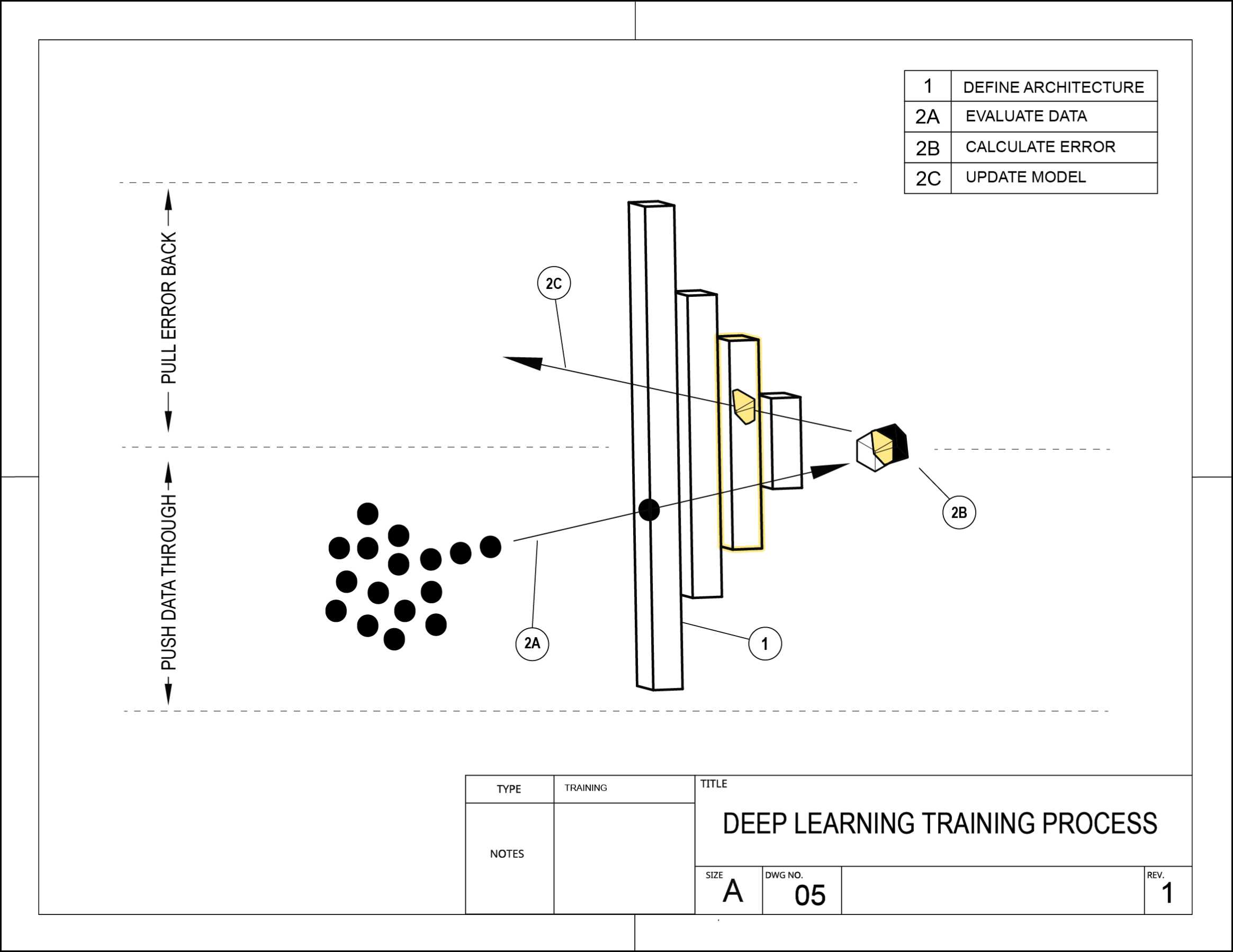
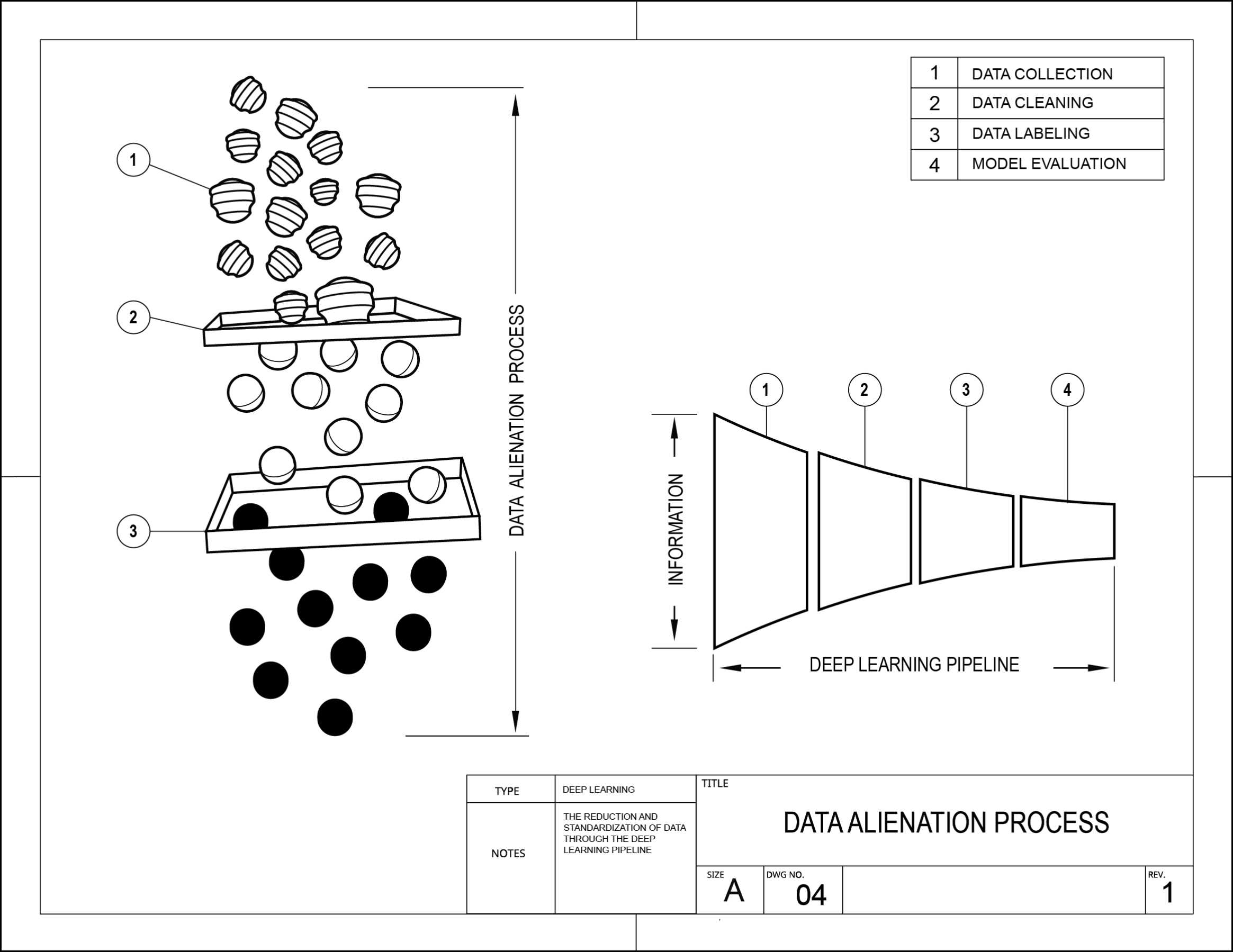
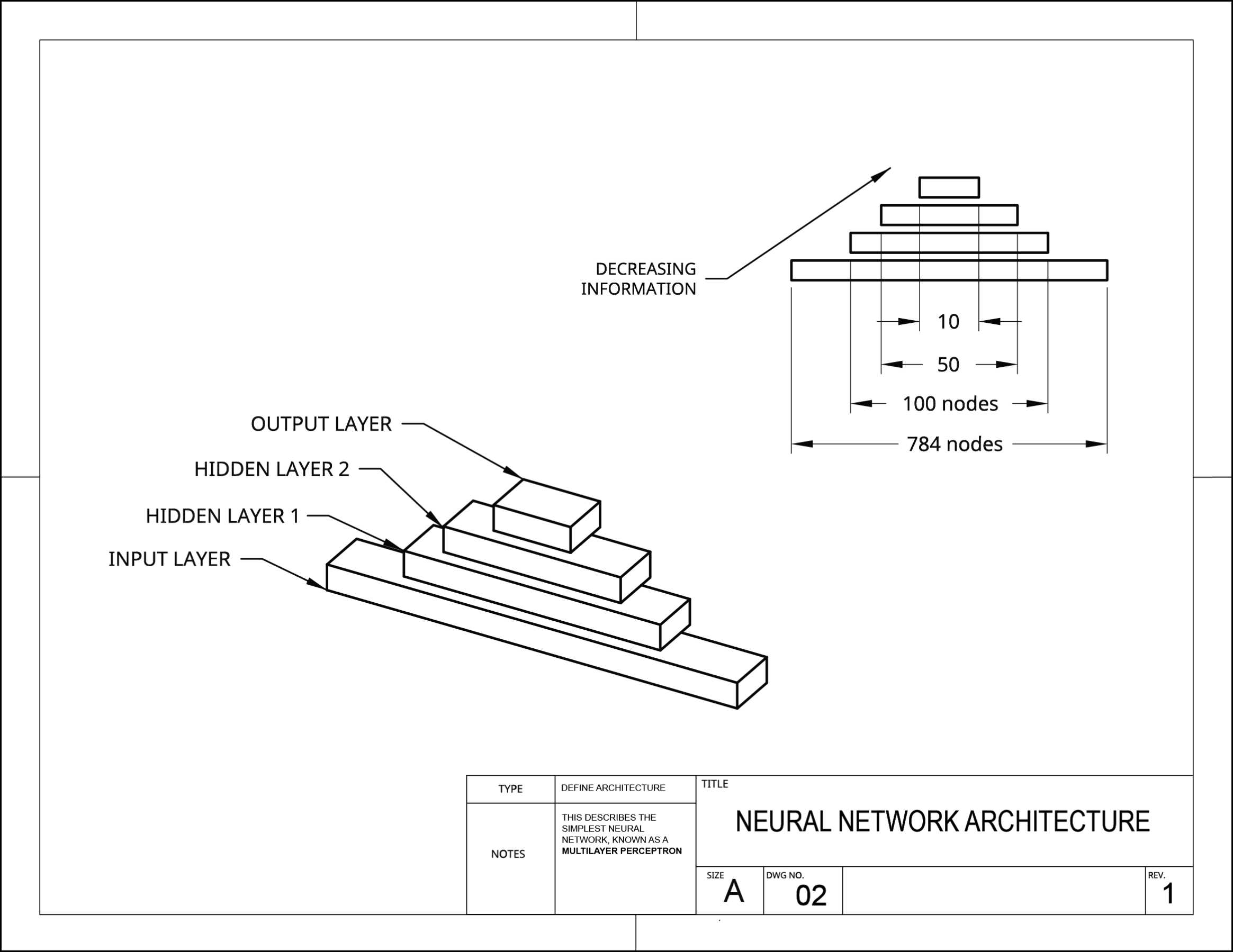
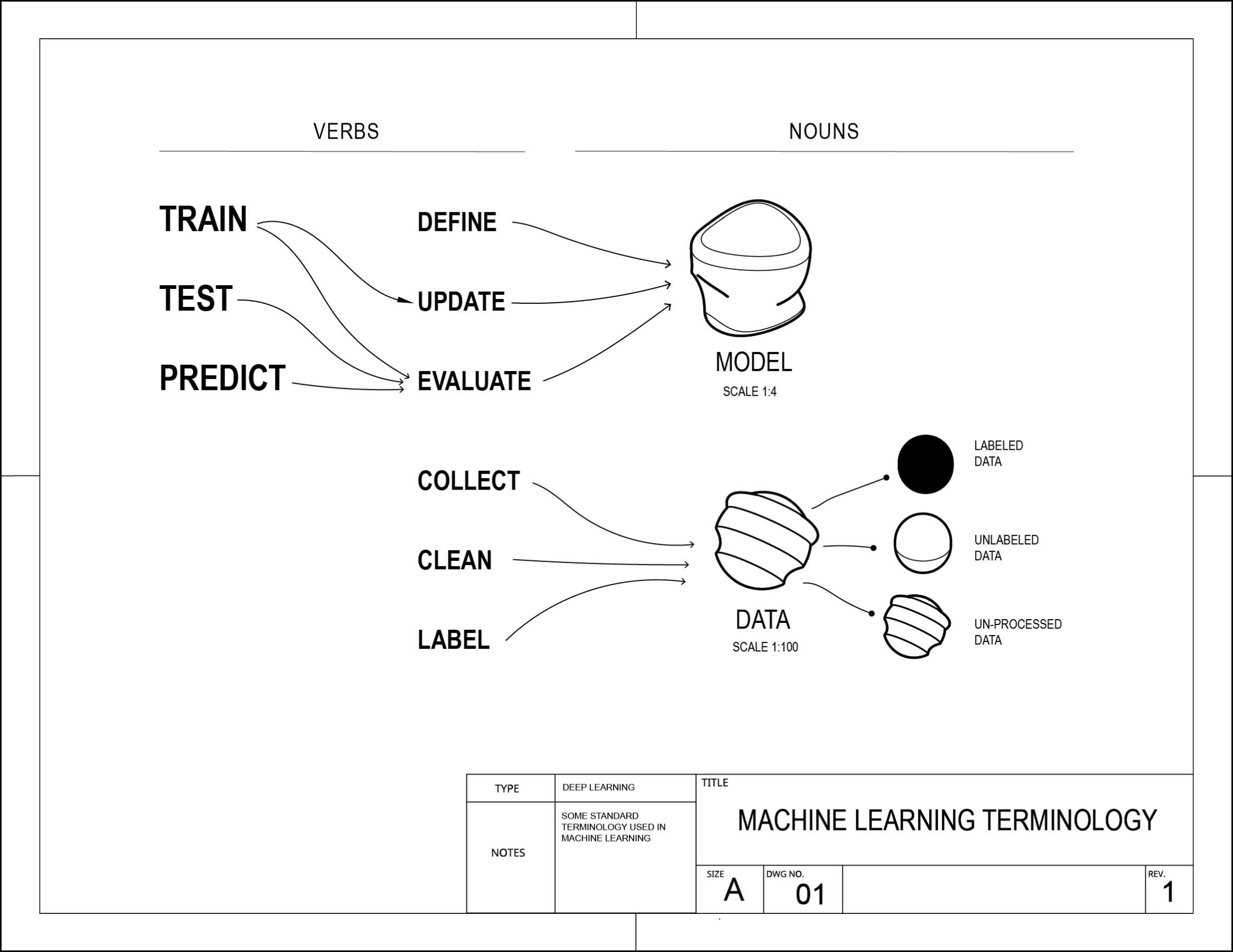

These diagrams were not primarily designed as communication tools. Instead, they served as a form of prototyping with ideas.
Developing Scenarios

The next phase of work was to do some synthesis of the broad range of research by creating specific scenarios that would put some of those initial explorations into particular contexts as a way to dig deeper into the subject matter.
From the initial research, I chose to focus on research threads on the process of data collection for machine learning as well as themes of surveillance, safety, and policing from my experiences working on dismantling predictive policing.
The scenarios I developed responded to the prompt:
What would data collection devices that collected data on fear look like? And how might you intervene in such data collection systems?


To address this brief, the research effort became more focused on mechanisms for collecting data. In this case, the research involved prototypes as well as secondary research on the material qualities of various data collection devices.

The development of the scenarios emerged through the prototypes I created. As the prototypes gained fidelity, I also began "prototyping" stories of the near-futures where these devices would exist, filling in details of the entire system of data collection.
To see a more detailed look at these scenarios, take a look at the Machined Data project page.
Scenario 1: Municipal Data Collection
The first scenario imagined a municipal "Data Surveyors" program, where residents participated in a "fear mapping" of their neighborhoods, which would impact where resources were deployed.


It posed questions about the subjective nature of data representing "fear" as well as questions about whose data would be collected in a program like this.
Scenario 2: Corporate Data Collection
The second scenario was focused on corporate data collection, imagining a system where a big tech company allowed users of home security technology to train their own algorithms to automate their cameras.


This scenario imagines people intervening in such a consumer system by "re-labeling" the default categories provided.
A key insight that came out of this scenario work was:
Machine learning is a process of worldbuilding facilitated by the labeling of data. Each algorithm is fed data to generate a computational vision of the world, which is deployed into the world as if it reflects reality.
While these scenarios largely just communicate a critique of machine learning systems, elements and themes developed for these scenarios were key parts of imagining entirely new, more experimental approaches to machine learning.
Moving from Research to Concept
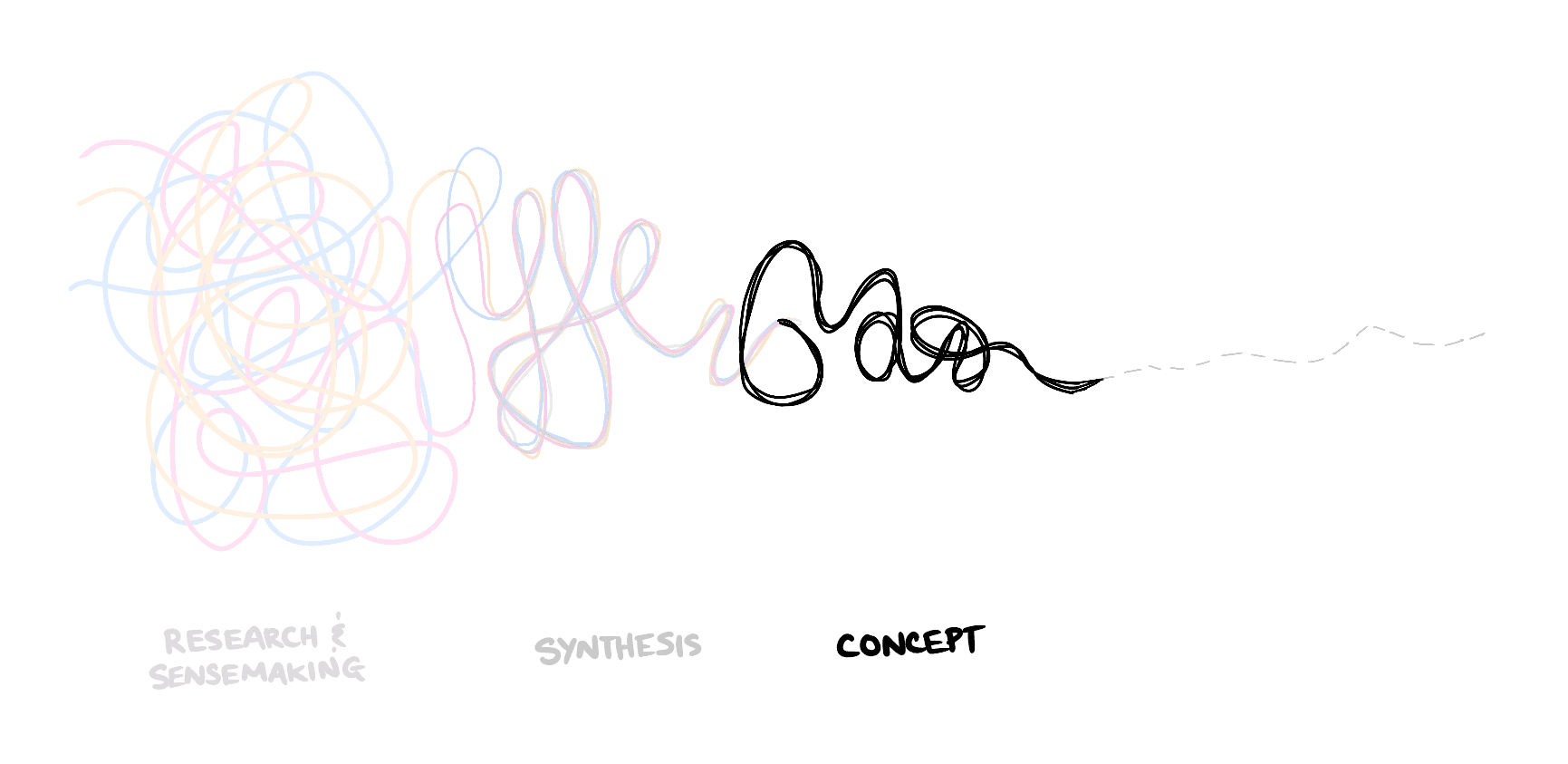
Up until this part of the process, the design work was largely about exploring and critiquing existing machine learning systems. The next step was to pull together all the insights from those explorations into new concepts for machine learning.
Feeding an algorithm fictional data could be used to generate aspirational worlds.
Building from the insights I found while developing scenarios, I realized that feeding an algorithm fictional data could be used to generate aspirational worlds. I sketched out an initial prototype for users to create imaginary data ontop of google street view:
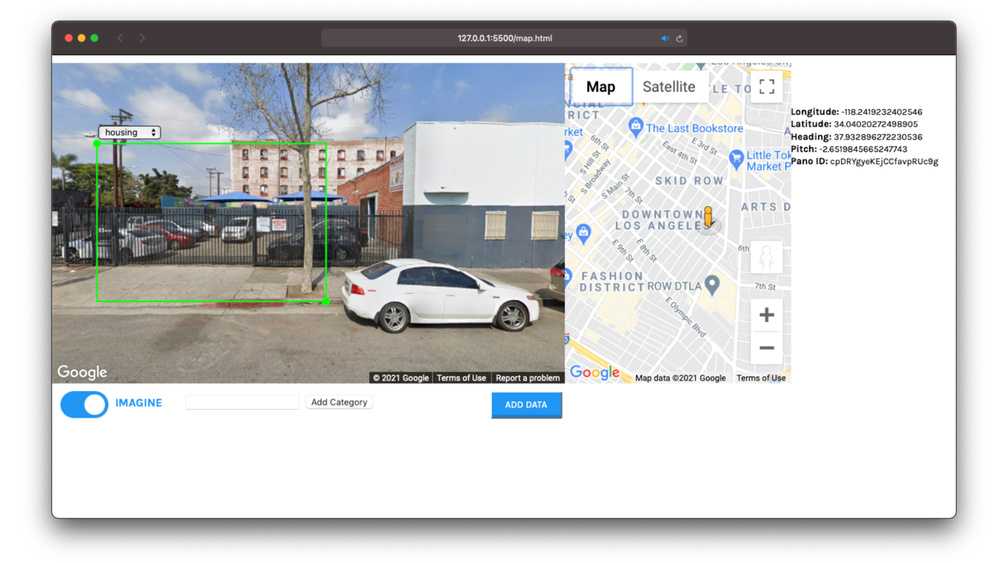
The design brief then became how do you prompt users of this tool for imaginary data? How do you spark their imagination? I developed the following variations to try to answer that question.

First Prototype
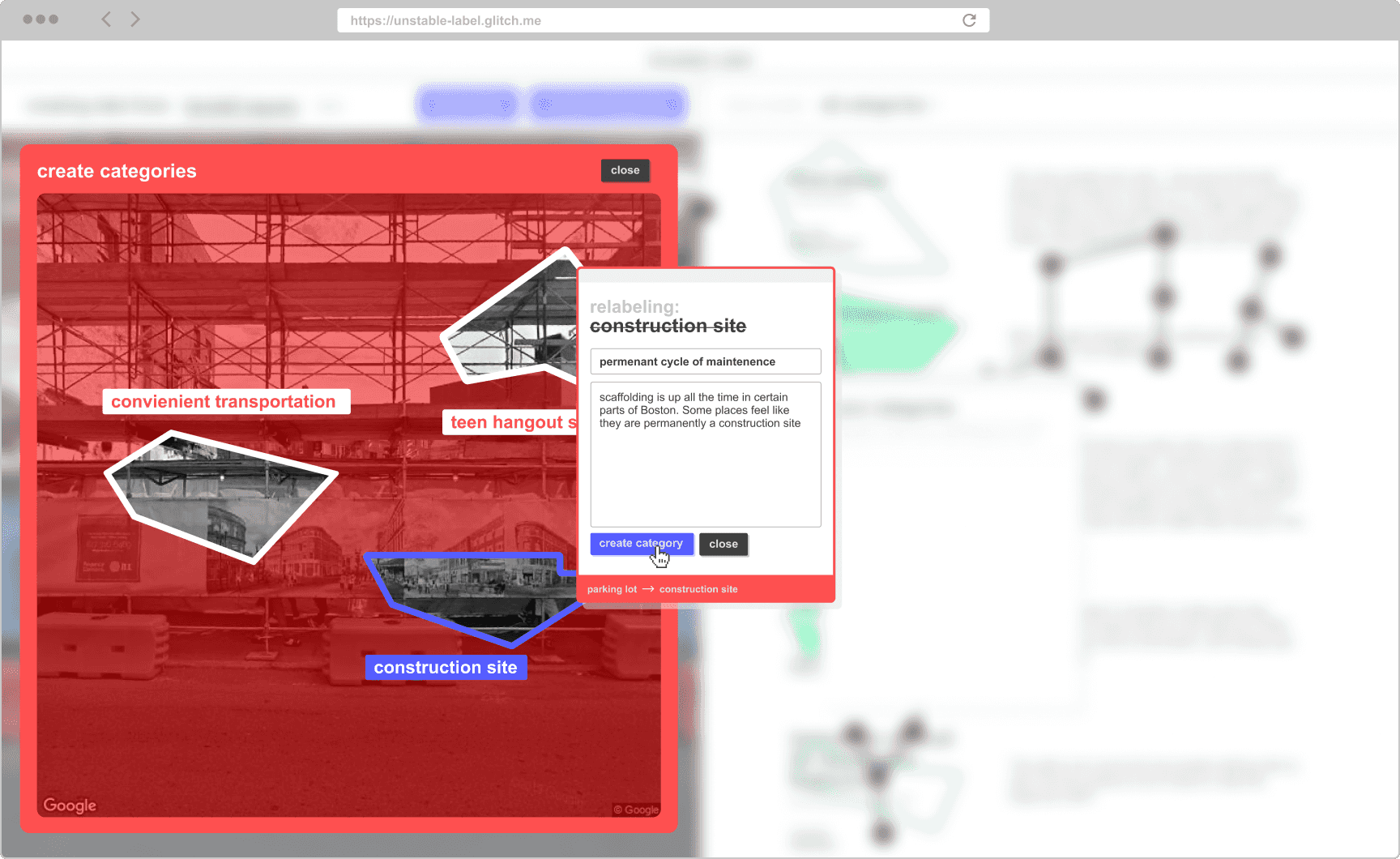
The most promising and intriguing approach was using the idea of relabeling, a theme which first appeared in the early phases of this design research.
The first prototypes of this data labeling application design around relabeling are shown below. For a user to label data, they had to create their own categories instead of using ones that were pre-defined for them.
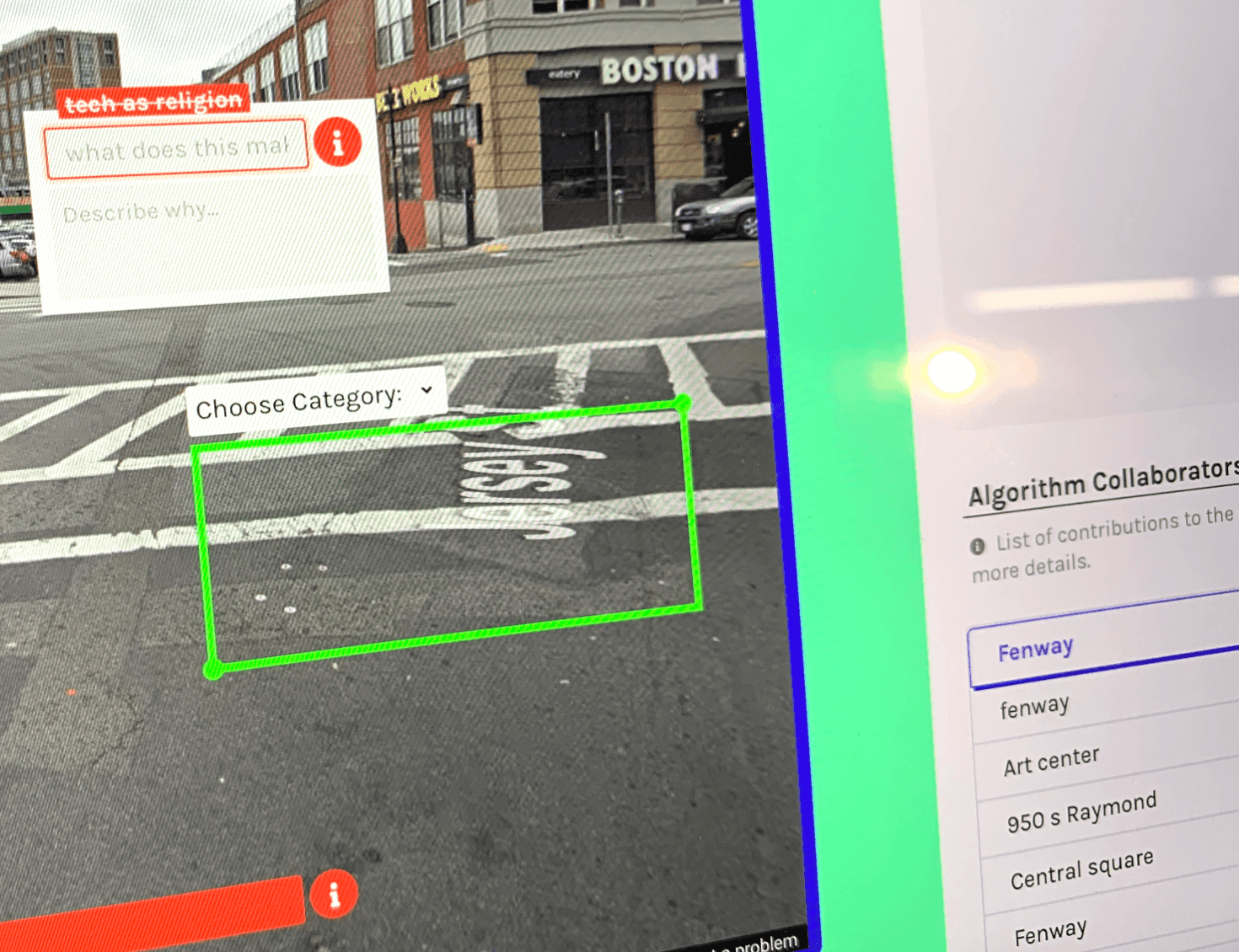
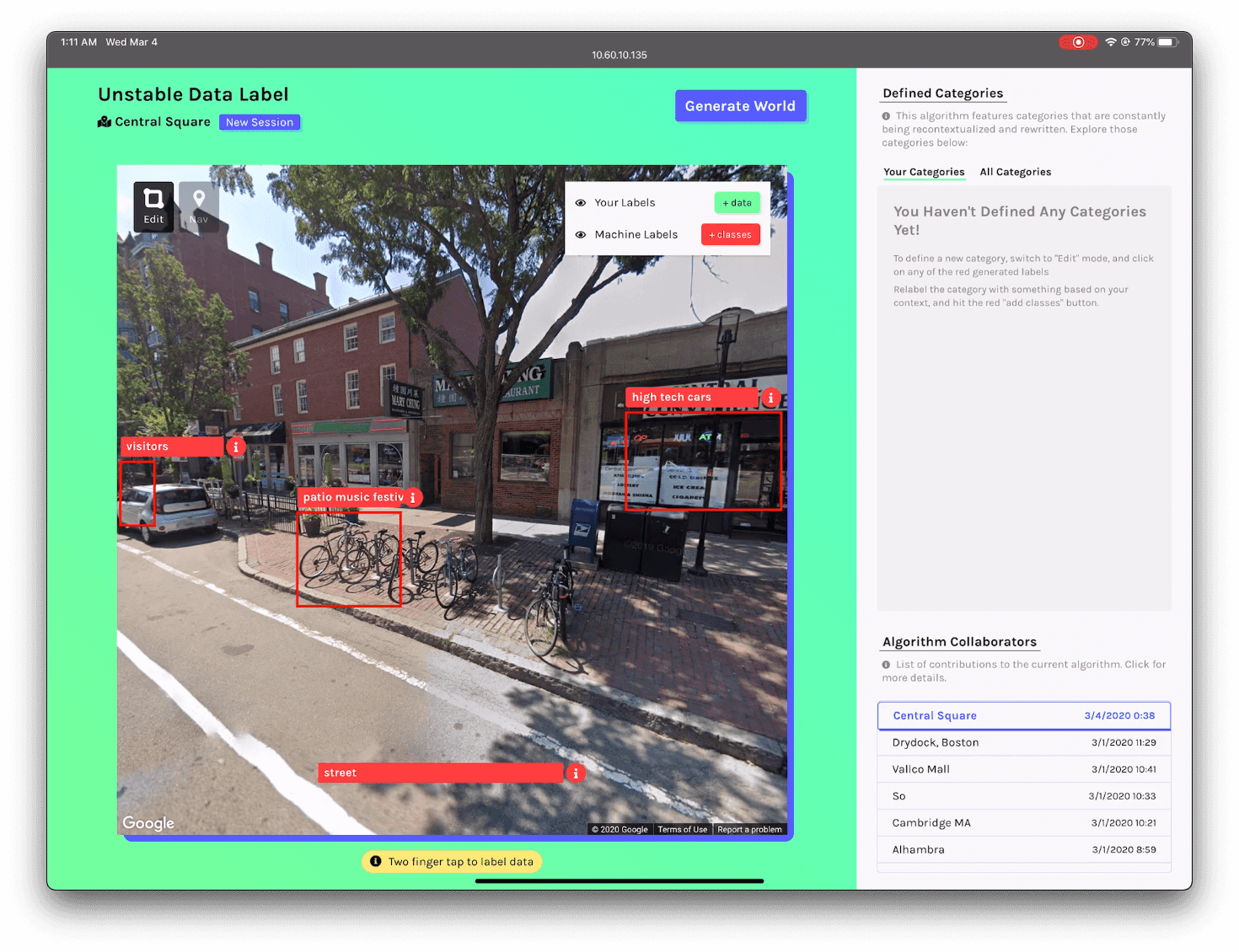
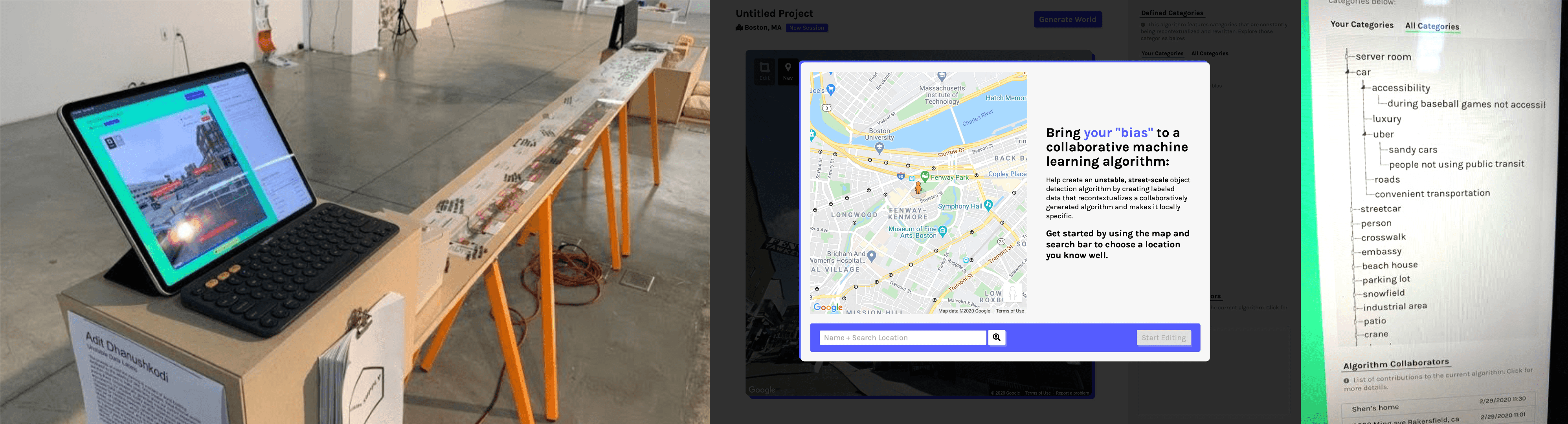
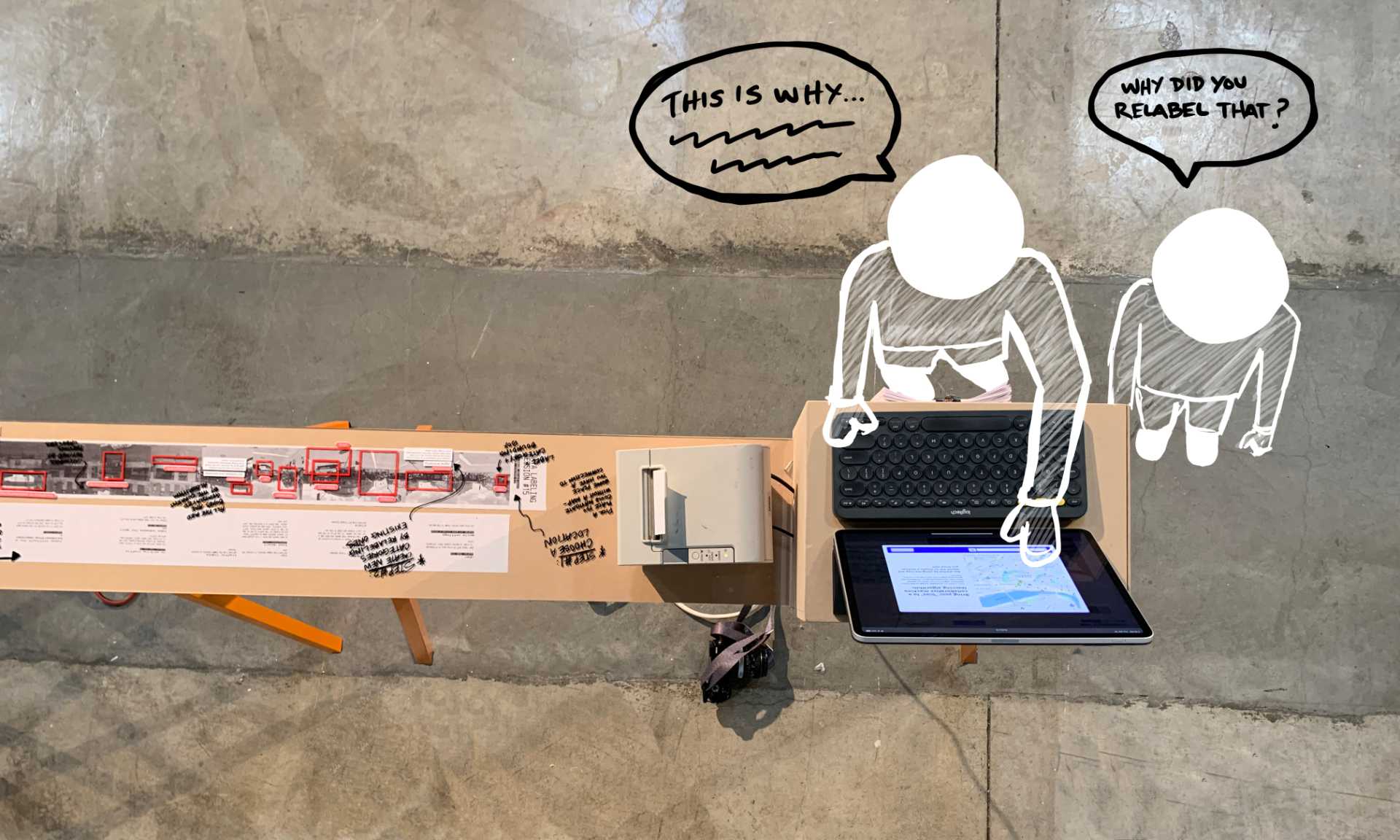
This prototype was used as a part of a physical installation that illustrated the re-labeling concept at the ArtCenter Media Design Practices Thesis Show.
Testing the Experience
The prototype, gallery show, and thesis presentation allowed me to test the concept.
The big insight from testing was that the "descriptions" written by the contributors, which represented the stories behind the relabeling, was the real "data" being collected, not the newly labeled images.
The key insight was that the written descriptions are the real "data" being collected, not the labeled images.
Detailed Design
Following the gallery show, and testing of the prototype, I began to develop the next iteration of the app focused on the visual aesthetics of the software. How would I represent the ideas at the core of the concept through the visual aesthetic? And how could I enhance the main features to highlight the stories behind the data?
How would you represent the concept and ideas in the visual aesthetics of the app?
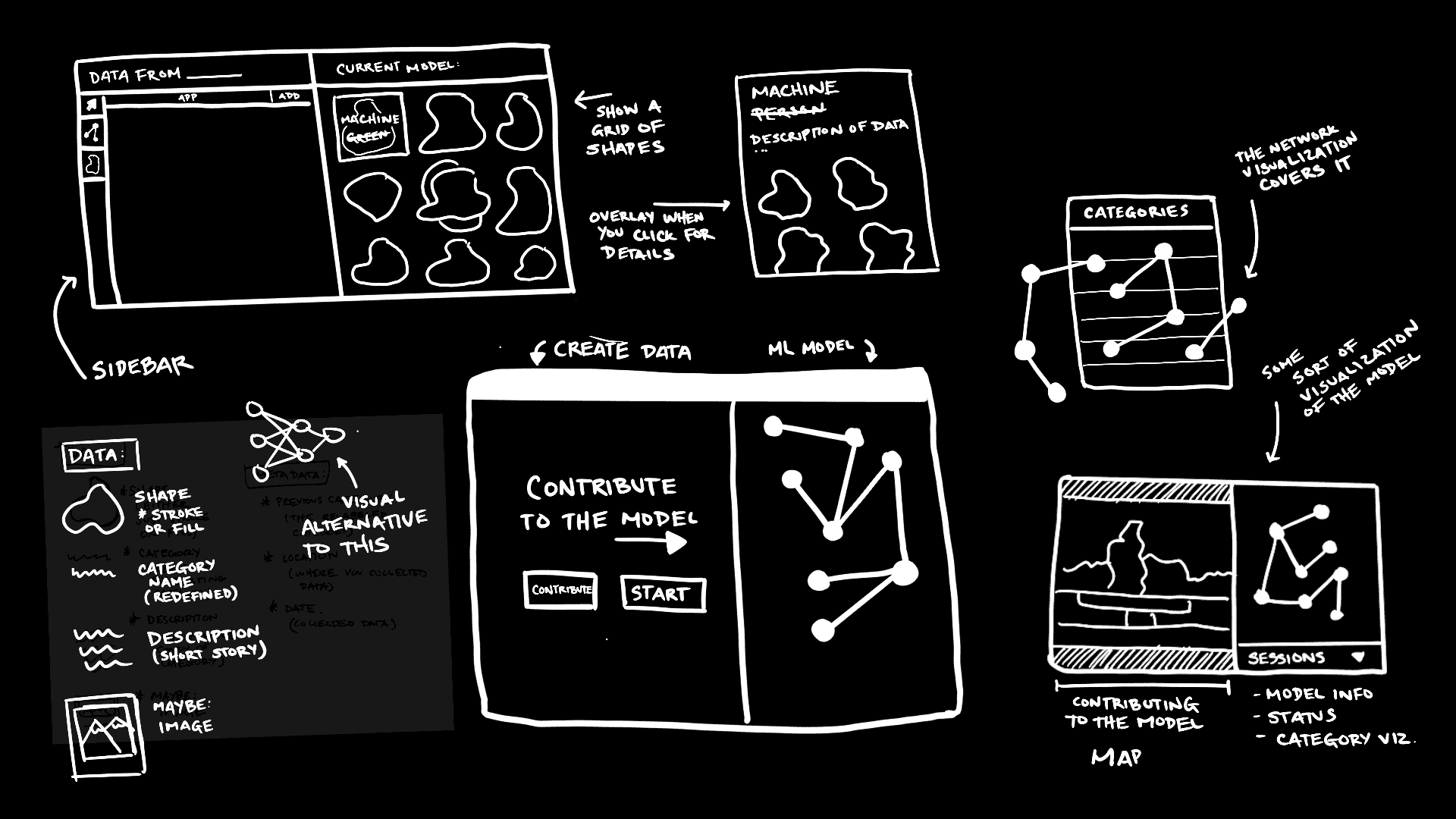
Some of the design explorations I went through can be seen in the sketches as well as Figma mockups illustrating some of the flows I explored.
Final Prototype
The final prototype was developed into a working prototype with an associated user manual, which explains to users how the system works. Some of the key changes and additions made to the design are outlined below.
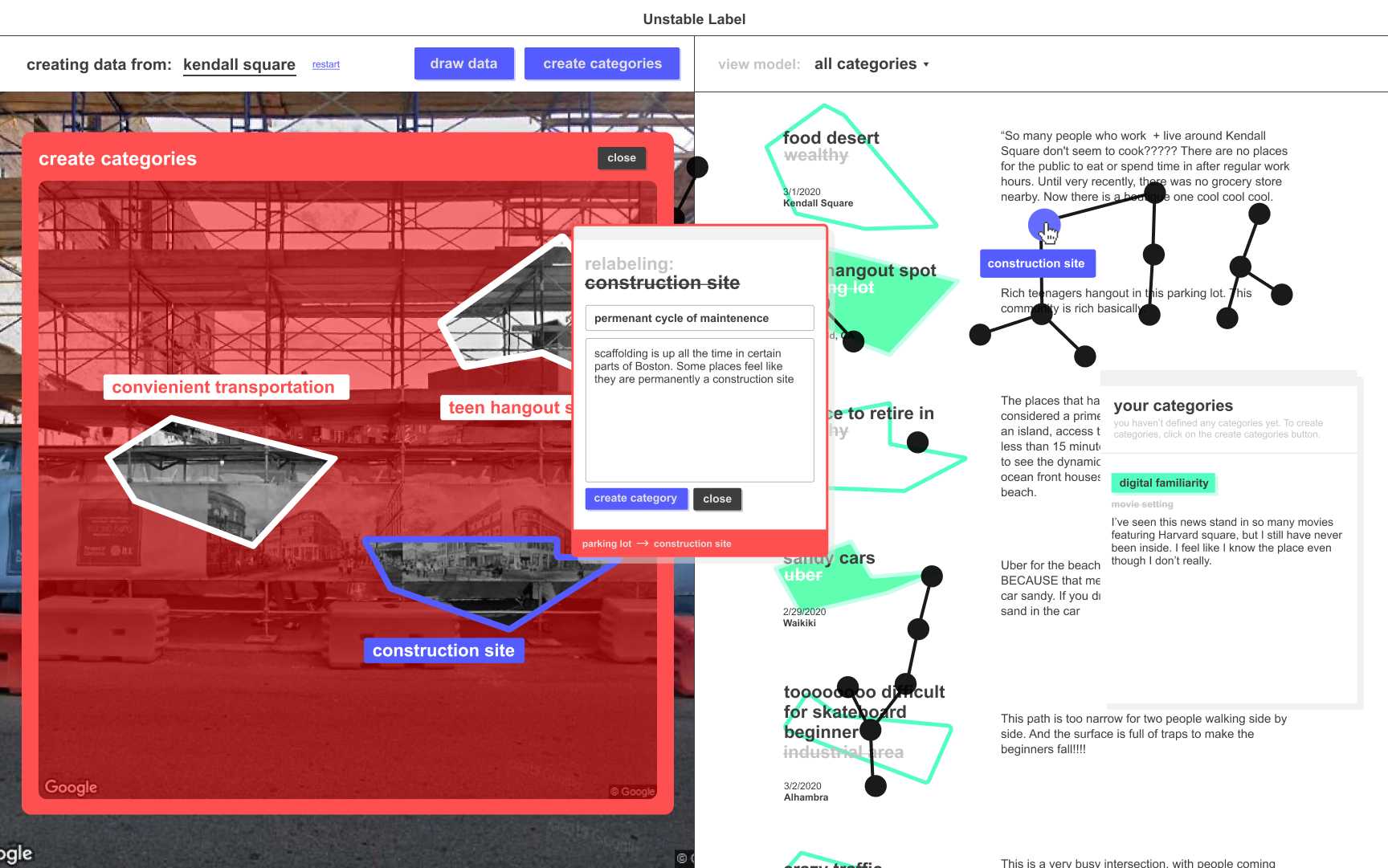
- Using lots of overlapping UI elements to represent the real messiness in developing categories for a machine learning algorithm.
- (Left) Pointing towards a future iteration of the app, where users could bring their own data instead of just using google street view
- (Right) Using user-drawn bounding boxes to show visualize existing labels


- (Left) Allowing users to draw bounding boxes freehand instead of resizeable rectangles.
- (Right) Representing the “model” as a network diagram showing the branching nature of the categories used
This resulting application represents an experimental approach to machine learning. It serves as a provocation and represents a set of critiques of contemporary machine learning’s approach to data collection.